



AWS S3 has long become a standard for storing file object data. Despite the many efforts in making S3 secure, we continue to see data in private buckets exposed or exploited in novel ways over the years.
Just how many ways can I trip over my own buckets (and spill the data)? Short answer: too many.
To start, here's a checklist of a dozen key security configurations and best practices that should be considered for S3:
- Enable server side encryption for data-at-rest.
- Enforce "aws:SecureTransport" via bucket policy (deny non-TLS/HTTPS requests)
- For buckets with critical data, enable MFA delete.
- Configure "Block Public Access" bucket settings properly.
- Tag buckets / objects with Classification and Owner.
- Enable server access logging or logging with CloudTrail.
- Enable event notifications to monitor for key changes.
- Enable cross-account cross-region replication on buckets storing critical data for disaster recovery.
- Leverage lifecycle configuration and versioning for resilience.
- Consider access restriction via VPC endpoints or PrivateLink.
- Identify and regularly review all IAM roles, users, and user groups with access to important buckets.
- Identify all buckets with public access and monitor whenever a new bucket is made public.
You've probably already seen the first 10 items of the above checklist somewhere -- in AWS security best practices or CIS AWS Foundations Benchmark. If you think you've got the last two items covered, think again. It may not be as trivial as it sounds.
Consider the following:
First, do you have an up-to-date inventory of all buckets across all accounts? Could a developer have created a new bucket or even a whole new AWS account without any security visibility?
Next, understand that an S3 bucket (or objects within a bucket) can be made externally or publicly accessible in multiple ways beyond just bucket ACLs and IAM policies. Some of them can be tricky to identify due to the complex, multi-hop and/or cross-account relationships among connected resources.
Here are some questions we should ask:
- Are there buckets granted access to someone outside of the owner account?
- Are there buckets granted access to public facing EC2 instances via EC2 instance profile?
- Are there buckets granted access to AWS services (such as CloudTrail, Config, Serverless Repo) without "aws:SourceAccount" condition to prevent potential cross-account attacks?
- Are there buckets accessible via cross-account VPC peering?
- Which Okta users have access to production S3 buckets via SAML SSO?
Last, how can we reduce false positives and further identify risks by knowing which buckets are supposed to be public and therefore: a) filter out those exceptions and b) ensure those public buckets do not contain sensitive data or secrets?
These questions can be difficult to answer and timing consuming to keep up. But there is a better way. If we take a relationship-focused approach in looking at the bucket configurations, access policies, connected users and resources in a graph, we could easily query and traverse the graph for answers. We can also set up continuous monitoring to detect drift and changes using these graph queries.
Let's look at some examples.
The following examples are done using JupiterOne (free, lifetime license), although you should be able to achieve the same results yourself using Neo4j or some other graph technology if you choose to.
Question 1:
Are there buckets granted access to someone outside of the owner account?
Query (J1QL)
Find aws_s3_bucket with _source!='system-mapper' as bucket
that ALLOWS as grant * as grantee
(that ASSIGNED * as principal)?
where
bucket.accountId != grantee.accountId or
(principal._type!=undefined and bucket.accountId != principal.accountId)
return tree
Graph (with sample data for Question 1):

Question 2:
Are there buckets granted access to public facing EC2 instances via EC2 instance profile?
Query (J1QL)
Find Internet
that allows aws_security_group
that protects aws_instance with active=true
that uses aws_iam_role that assigned AccessPolicy
that allows (aws_s3|aws_s3_bucket) with classification!='public'
return tree
Graph (with sample data for Question 2):

Question 3:
Are there buckets accessible via cross-account VPC peering?
Query (J1QL)
Find (aws_s3|aws_s3_bucket)
that allows aws_vpc_endpoint
that has aws_vpc as vpc1
that connects aws_vpc as vpc2
where
vpc1.accountId != vpc2.accountId
return tree
Graph (with sample data for Question 3):

Question 4:
Are there buckets granted access to AWS services without the "aws:SourceAccount" condition?
Query (J1QL)
Find aws_s3_bucket as bucket
that allows Service
with name = ('serverlessrepo' or 'cloudtrail' or 'config')
where
allows.conditions = undefined or (
allows.conditions !~= 'aws:SourceAccount' and
allows.conditions !~= 'aws:PrincipalOrgId' and
allows.conditions !~= bucket.accountId)
return tree
Graph (with sample data for Question 4):

Question 5:
Which public buckets may contain sensitive data or secrets?
Query (J1QL)
Find (Everyone|aws_cloudfront_distribution)
that (allows|connects) aws_s3_bucket
that has Finding
with hasSecrets=true or
hasSensitiveData=true
return tree
Graph (with sample data for Question 5):

Question 6:
Which Okta users have access to production S3 buckets via SAML SSO?
Query (J1QL)
Find okta_user that assigned AccessRole
that assigned AccessPolicy
that allows (aws_s3|aws_s3_bucket|aws_account) with tag.Production=true
(that has aws_s3)?
(that has aws_s3_bucket)?
return tree
Graph (with sample data for Question 6):

Automated Data Analysis
Most of these questions are not that hard to answer, once you know what you are looking for, in a relatively simple and small environment. However, once your operations expand to multiple AWS accounts -- sometimes hundreds or even thousands of accounts, with potentially millions of resources across the entire environment, this can become an impossibly challenging task.
The only way to identify the issues, and to continuously monitor them, is with automated data analysis.
With JupiterOne, you can easily turn this:
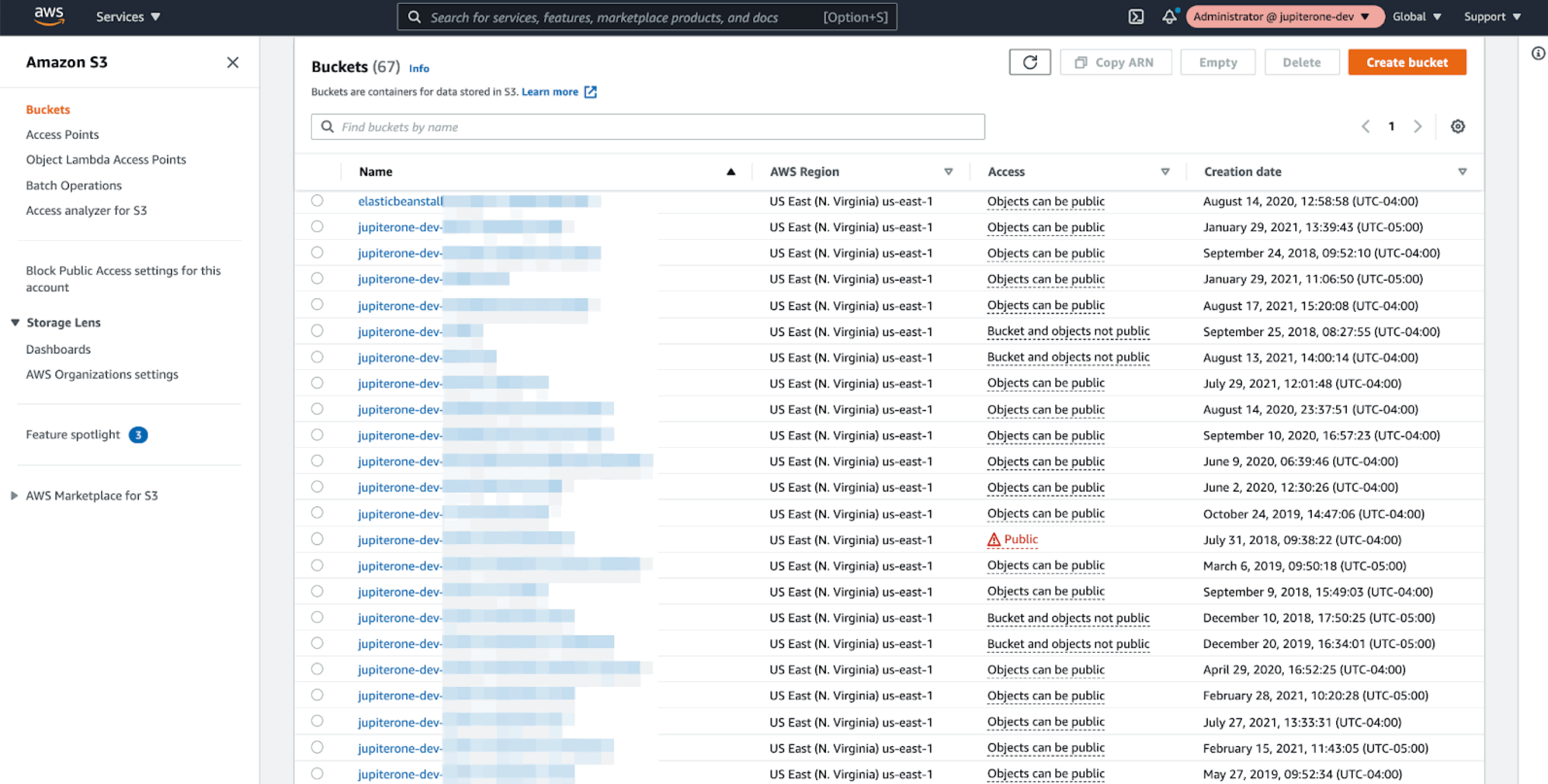
Into this:

Conclusion
I'll leave you with this: let's not forget the "shared responsibility model" between cloud providers (AWS, in this case) and cloud consumers (you). While AWS secures the infrastructure behind the scenes, they also make it very flexible for you to configure the resources and their access.
Understanding this flexibility and applying controls properly is your responsibility. Yet this amount of flexibility can sometimes get in the way and complicate things. That's why I have long been an advocate of using a graph data model and automated data analysis to assist.




